SNCF Connect: Flutter pipeline optimization with Very Good Test
During the early development of the SNCF Connect app, the development team had to deal with a lot of different machines. At that time, we had every kind of platforms: Windows and MacOS for the developers and mainly Linux for the CI (but also macOS, but only for the iOS release).
These heterogeneous platforms were a problem then, because we made the choice to use Golden tests inside our mobile project.
Golden tests for Flutter is a powerful tool, developed by Ebay. We used that tool to help detect UI regressions through UI tests. The interface is completely generated with the help of golden_toolkit and the Flutter framework.
Early time of the project : Docker to the rescue
It is possible to use Golden tests with heterogeneous platforms, using Ahem font, but this is not optimal.
Why use Ahem then? Because when you work with multiple OS, the process of font rendering can differ — an image generated on one particular OS can be different on another OS, as you can see below.

Ahem font is insensitive to platform switch, so you could eventually use it, but in our case, we wanted to use the “production” font, for essentially two reasons:
- Ahem doesn’t detect text regression: for instance, a “q” can be replaced by a “p” and the golden test will be fine, but we’ll have a text regression.
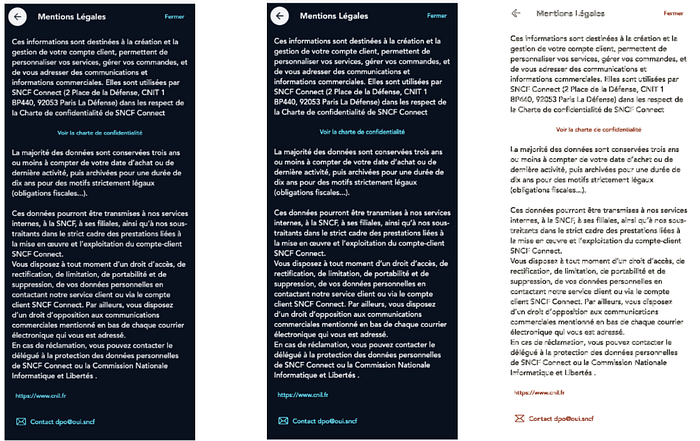
- In some screens, it can be difficult for a human eye to see a regression or to understand a screen (you can find an example below).

To address these issues and use the production font, we made the choice to use Docker to homogenize our platforms. This solution was not perfect, but in the early times of the project, it helped the development team to postpone this problem, use the correct font for the tests, improve the delivery time, and detect regression.
The project growth and the CI problem
During the development of SNCF Connect, the more the project became mature, the more the test codebase grew, and so did the CI. It got to a point where we had to make a decision because of the slowness of the mobile pipeline.
The horizontal division of tests with multiple jobs through the CI was a good alternative, but it came with two main problems:
- We had to maintain the CI yaml file: when we added a new test repository for example, we had to remember that we needed to update the CI test file to execute the newly added test.
- the distribution of tests is done on the fly; it wasn’t even, timewise.
In our case, we split our tests into nine jobs, each job executing a sub-set of tests.
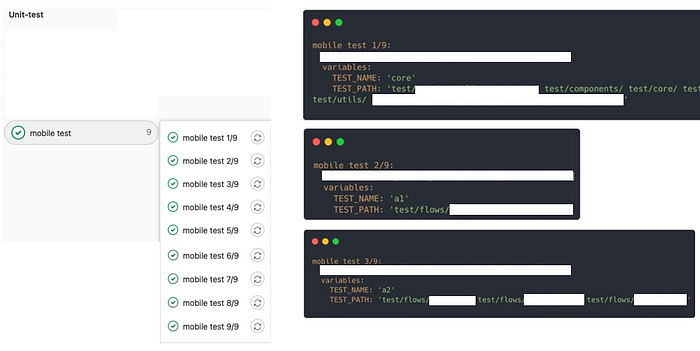
This solution wasn’t a thing — we greatly doubted of its scalability in the long run — but again, Very Good Test wasn’t out at this time (0.6.0 was out in March).
The problem of the test job duration was solved for a while with this solution: we could develop and test features, and had a better “fail-fast” system, because we could see if a job was failing without having to wait for the entire job to fail. But really we were postponing the real problem: the platform heterogeneity.
When horizontal division is not enough
The horizontal division was a good temporary solution, but as the project was still growing, we rapidly saw that the CI mobile test jobs were part of the top ten longest jobs of the entire CI of the mono-repository, which — obviously — wasn’t what we wanted.
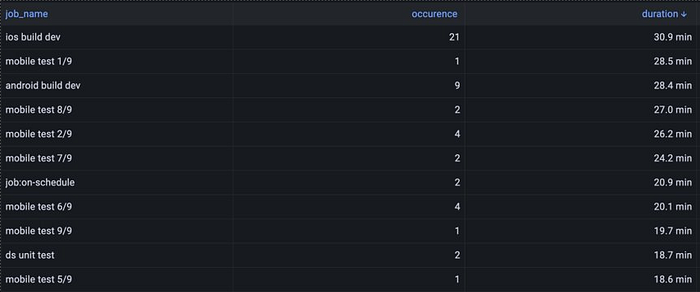
It took up to 200 minutes to completely run the tests of our project, which was way too long, considering that there were 3k tests.
Another problem was directly on the developer’s computer: Docker wasn’t fully compatible with the latest Apple Silicon, so we created a flutter-test-remote script to execute the entire test codebase of a branch on an AWS pod, but as you can imagine, it can be very slow.
Time to measure Docker executing Flutter test vs classic Flutter test
The first thing we wanted to measure was the impact of Docker on the tests, and it did have an impact:

In addition to this first result, we updated our golden_toolkit (0.9.0 to 0.13.0). This new version allowed us to either target the golden tests only, or exclude them. We wanted to try to use this tool to quantify the amount of time a golden test took compared to a widget test or a unit test.


A golden test takes a lot of time compared to a classic test: on my mac mini (2018, i7, 32go) it takes an average of 1.07 second for one golden test to be completed, when it takes approximately 0.20 second for a classic Flutter test to complete. So indeed, a golden test is more time-consuming than a classic golden, but in our case, we had a “custom screen test golden” which generated 4 files (a11y, iphone11 light mode, iphone11 dark mode, semantics).
With this in mind, we determined that we could:
- Remove Docker because of its negative impact on the tests duration, and its incompatibility with Apple Silicon.
- Limit the creation of new goldens, and clean / merge the old ones in order to rationalize the tests.
- Use the IDE, don’t run script to launch tests (it was convenient/necessary with Docker).
- Reorganize the CI Jobs: keep it super simple, with less than 9 jobs running, and no more yaml file to update when adding a new repertory.
Optimization with very_good test
With very_good test, there is no black magic. It’s just a tool on top of the classic flutter test command, but it’s all about the way this command is used. Its creation started with a statement of Liam Appelbe on the flutter repository.
The test framework runs each test separately and gathers coverage data for each test before merging all that data into a single report
So if you have a large test suite for a densely interlinked project, this will mean something like O(test_files * project_files) getSourceReport RPCs. If we could run all the tests in a single isolate, this would reduce to O(test_files + project_files).
The objective is to gather the test files and execute them into a single Isolate to reduce time and energy consumption. In fact, this is exactly what’s very_good test doing. When you launch the command very_good test, the tool merges all the *_test.dart files into a single .test_runner.dart.

The challenge of a single Isolate — testing tightness
With VeryGood we can push things further and improve the tests in local as well as in the CI, so what’s the point of going without?
In fact we struggled to put very_good in place because with a single Isolate, we must be careful with “the neighbors”.
The static field
The first difficulty was to mock some static behavior like FlutterError.onError or ErrorWidget.builder used in our project. It’s necessary to keep a reference to the previous value in order to restore the “default” behavior.
If you don’t do that, you can have unexpected results in the tests that don’t use this class directly. For instance:
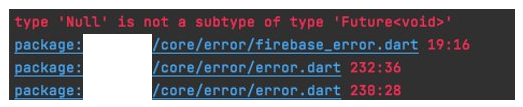
Here you can see an example of a trivial restoration of static value in a group test:
Singleton
During the adaptation of our codebase to very_good, we got through a lot of GetIt errors like : “Object/factory with type X is not registered inside GetIt.”
In fact, this kind of error was very strange until I came across this code snippet :
This was one of the first tests to be written by our team during the development of SNCF Connect. I wasn’t sure about the purpose of this code — especially in the context of the test it came with — but it didn’t seem to be useful, so I removed it. This test ran fine with or without very_good.
After that, the migration of the rest of the code base was trivial.
Results on the local machine
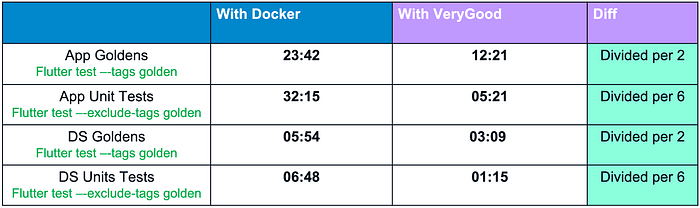
You can find the results bellow :

We saw a big improvement on a local machine when removing Docker, but this improvement could be increased by the use of very_good. It helped us have about 7% gain.
CI Improvement — Remove the horizontal division
With this improvement, we were able to improve our CI. We decided to replace all nine mobile test jobs with only four new ones. Two jobs were allowed for the app Design System, and two others for the app testing itself.
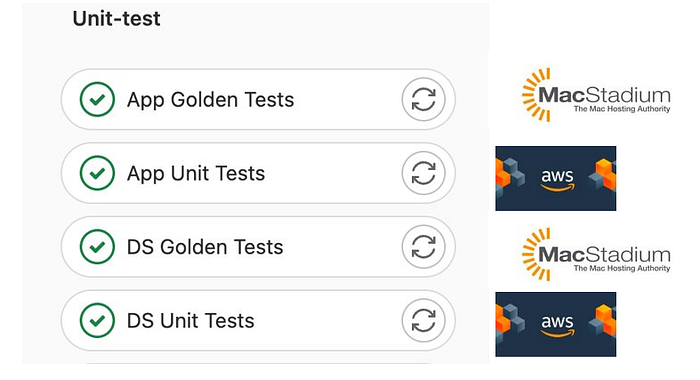
We made the choice to keep the golden tests for a macOS platform (executed on MacStadium) while our non golden tests could be run on any machine (and not necessarily a Mac).
In the meantime, we decided to save every macOS machine for the flutter developers team.
On the CI, we also saw a big improvement of execution time as you can see on the table below:
Current limitation of Very Good (at the time of writing)
- No machine mode option: you have to adapt your CI if you use this mode before (a PR is open here).
- The last version of very_good requires dart and flutter to be updated (be careful if you use fvm in a non global version). Thanks to the verbose mode you can see why very_good crashes at runtime.
The tracks that were not successful
- Ahem font: as seen previously, we tried to use Ahem font, but unfortunately this font doesn’t help in text regression.
- Alchemist: We decided not to use it for the same reason as Ahem. However, you can find a great article about Alchemist here.
- Custom pixel comparator: unfortunately, in some screens we had more that 14% of pixel differences (GCU screen for example). At this point, the custom pixel comparator is not reliable.
I would like to thank Abdelaziz Gacemi for his help on this subject. I hope that you enjoyed this article and that it will help you in the optimization / update of your CI :) .
